SilverGait AI Innovation Challenge 2026
Last updated: Apr 9, 2026
Tools: gemini · langgraph · elevenlabs
SilverGait runs a clinically-validated frailty assessment from a phone camera. Seniors do balance, gait, and chair-stand tests at home, pose extraction and a deterministic classifier handle the scoring, and a multilingual chat agent handles follow-up. Built over 9 weeks for the AI Innovation Challenge 2026, where it placed 2nd.
How it started
The project came from one of my teammates, a pharmacist at Singapore General Hospital, noticing how much clinical time goes into frailty assessments. The Short Physical Performance Battery is a standardized test for community-dwelling seniors, and it needs trained eyes. It doesn’t scale. He brought it to the team and we workshopped it from there. Six of us, all NUS MSBA.
Healthcare in Singapore is personal to us. Our parents and grandparents use it. This was our healthcare system, our problem to solve, and we weren’t going to half-ass a project on aging Singaporeans. That’s not a strategy, it’s just how we felt going in.
The click moment came nine weeks in, when we tested SilverGait on ourselves, in Singlish, sitting on chairs in a meeting room at NUS. The joint tracking caught the chair-stand timing, the scoring spat out a number, and someone laughed and said “wait, this actually works.” Not the most accurate run we’d ever do, but accurate enough that the system was doing what we built it to do.
What it does
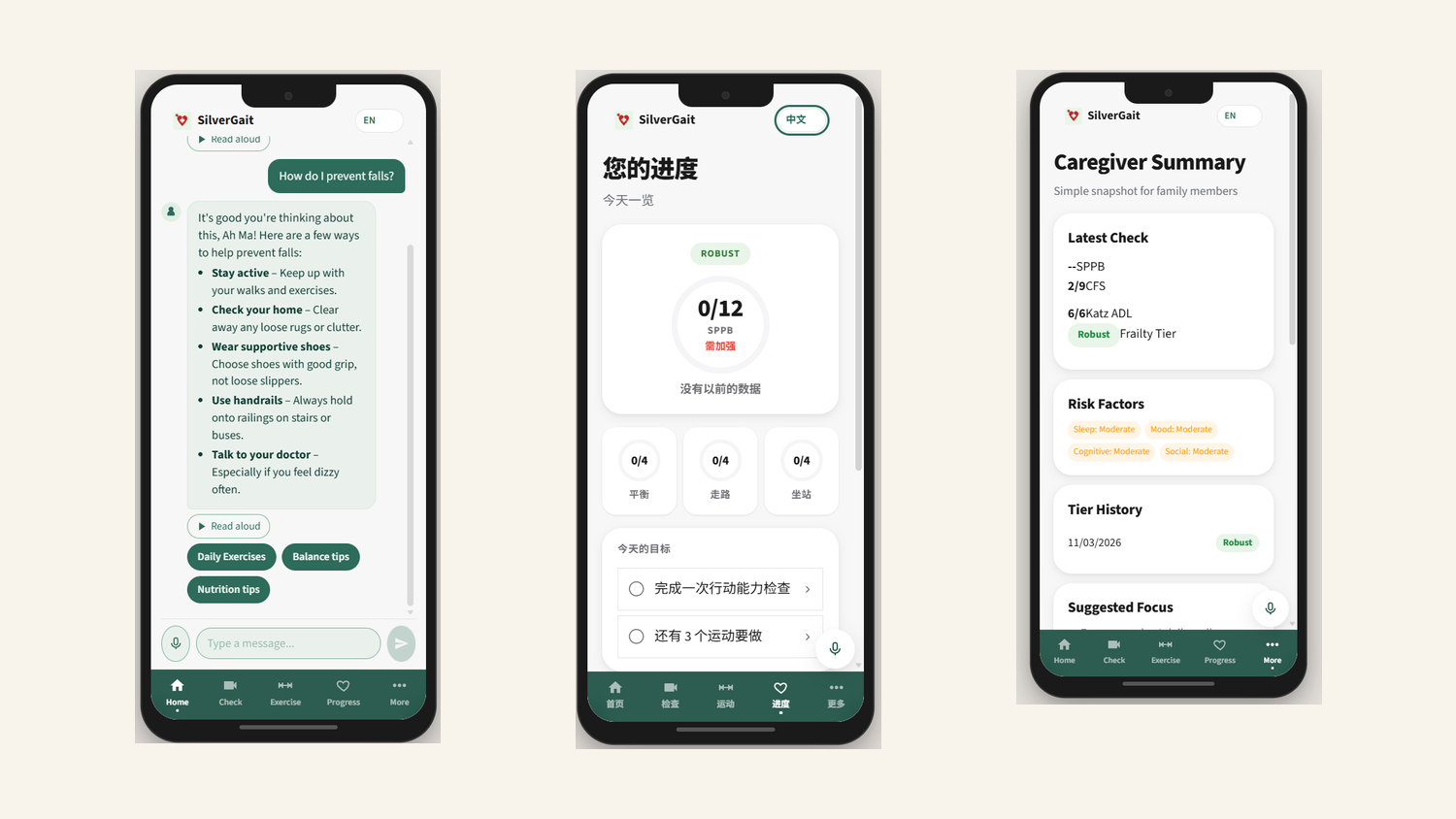
A senior opens the app and is guided through the SPPB (balance stand, 4-metre walk, chair-stand). The phone camera records each component. MoveNet extracts 2D keypoints on-device, and Gemini Vision evaluates the keypoint trajectories against the SPPB rubric to produce sub-scores in the 0 to 12 range. The system combines the SPPB result with Katz ADL and Clinical Frailty Scale inputs to assign a frailty tier.
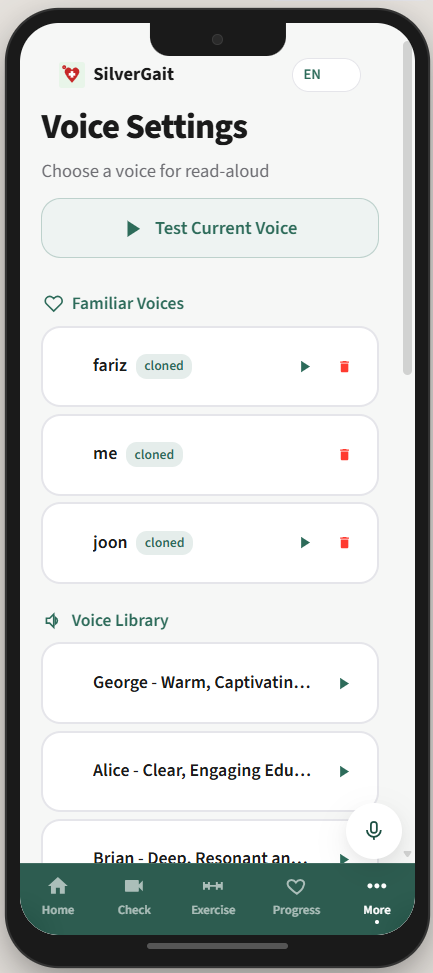
If the tier changes (better or worse), the system auto-generates an updated care plan: an exercise plan tuned to the frailty level, a CBT-I sleep plan from the Sleep Agent, and a caregiver alert if the change is concerning. All explanation, follow-up, and Q&A goes through a chat agent that speaks English, Mandarin, Malay, or Tamil. The TTS uses an ElevenLabs voice clone of someone the senior already trusts (a son, daughter, regular caregiver), so the assistant sounds familiar.
How it works
Two pipelines, intentionally split.
Assessment graph (zero LLM calls). MoveNet runs pose estimation on the recorded video. Gemini Vision scores the keypoint trajectories against the SPPB rubric. A rule-based classifier combines SPPB, Katz ADL, and CFS into a frailty tier. A tier change triggers care plan updates and caregiver alerts. The LLM is used as a vision evaluator, not a reasoner.

Chat graph (1 to 5 LLM calls). A Gemini 2.5 Flash orchestrator handles user messages and dispatches to sub-agents (Exercise, Sleep, Education, Monitoring, Progress Summary, Alert Caregiver) via function calling. Education uses a small RAG over peer-reviewed sources. A safety gate sits before any persistence step.
Voice and language. MERaLiON AudioLLM handles Singlish-accented STT, with Gemini as fallback for the other languages. ElevenLabs handles TTS and the caregiver voice cloning, with Gemini TTS as a fallback. The frontend (React 18 + Vite + Zustand + TS) is tuned for elderly users: 18px+ fonts, 48px+ touch targets, high-contrast palette, voice on every screen. Backend is FastAPI with async SQLAlchemy. LangGraph orchestrates both pipelines.
The voice cloning is a small detail in the architecture diagram and the entire UX in practice. The first time we played a cloned voice back, that was the moment the team understood what we were building was actually for someone, not just for the demo.
What was hard
The biggest cost was clinical grounding. Every design choice had to map to a peer-reviewed source: why these SPPB cutoffs, why Katz ADL alongside CFS, why specific exercise prescriptions per frailty tier. The papers existed but were spread across decades of geriatrics literature. We ended up with 35+ citations behind specific architectural decisions.
The second was being a non-CS team. We are NUS MSBA students. Most of the time spent on the project was on SWE plumbing, async/await debugging, deployment, and getting the multimodal pipeline to behave consistently. Claude Code did a lot of the heavy lifting.
The third was resisting the obvious shortcut for the scoring path. The fast version is “send the video to a vision LLM and ask for a frailty score.” The clinically defensible version is what we built: deterministic scoring backed by published rubrics, with the LLM strictly evaluating keypoint trajectories against rules. The first time you demo to a clinician, the second version is the one they trust.
What we cut, and what we’d change
The thing we cut early was a full agentic pipeline for the monitoring layer. We had ideas about tool-calling cron jobs, agents that “decide” when to run check-ins, but when we mapped the actual decisions, they were linear. Run check-in, if alert, notify caregiver. There was no agentic graph type shit needed. So we cut it and kept the orchestration where reasoning was actually load-bearing.
The bigger thing I’d change next time is real wearables integration. We scoped it in early and dropped it for difficulty. Frailty signals like heart rate variability and gait asymmetry over weeks live in wearables data. The phone-camera assessment is point-in-time, and wearables would close the loop. I’d also start with a smaller multilingual scope. We did English, Mandarin, Malay, and Tamil with MERaLiON for Singlish. It worked, but each language added testing surface area we didn’t have time to be thorough on.
Outcome
2nd place at the NUS x Synapxe x IMDA AI Innovation Challenge 2026. Live deployment at silvergait-production.up.railway.app.

The thing that surprised me most was how varied the team’s strengths were. I did the entire stack: backend, frontend, the Railway deployment, the API integrations. My teammates ran pitching, the clinical research, and the user study with seniors. Without their parts, the technical demo lands flat. Without my parts, the pitching team has nothing to demo. That’s obvious in retrospect, and not obvious at all when you’re 6 MSBA students staring at a competition brief.
Also: Claude Code is genuinely the reason a non-CS team ships a multimodal multilingual system in 9 weeks. I would not have written the FastAPI async + SQLAlchemy + LangGraph orchestration that fast on my own.
For the full clinical evidence base (35+ peer-reviewed citations), interactive LangGraph diagrams, and node-level architecture specs, see the SilverGait documentation site. Specific deep-dives:
Built with five teammates from the NUS MSBA cohort.